
为什么GoogleTranslate是突破性进展?|谷歌翻译
前言
本文主要介绍序列到序列。该技术主要用于文本理解和机器阅读。
过去一年,人工智能在应用领域有三大标志性突破:
首先,大家都知道,AlphaGo与韩国著名棋手李世石的人机围棋大战,突然打破了世界对人工智能的认知,发生了180度大逆转。以前,人们觉得人工智能不是很可靠。不切实际的概念,现在人工智能无所不能,说不定20年后人工智能会统治人类。你认为它会在 20 年后统治我们吗?我有点怀疑,但很多人认为这很可怕。
二是特斯拉上的特斯拉Autopilot辅助导航系统。虽然叫辅助,但其实是无人驾驶系统,因为确实有很多人上车后不握方向盘。这一事件标志着无人驾驶技术基本可以商业化,因此2017年无人驾驶行业一片狼藉。
百度开源,为什么?因为这场无人驾驶领域的较量已经进入下半场,上半场的任务是抢占先机,下半场的任务是杀敌,所以百度开源了,很多竞争对手消失了。这是百度。基本战略愿景。
三、谷歌翻译(Google Translate),自然语言翻译、汉译英、英译汉、汉译法等功能投入商业使用。
为什么谷歌翻译是一项突破?
我们今天要讲的是为什么这件事很重要,因为谷歌翻译已经用证据证明了一些事情:
首先是“跨语言”,任何自然语言,汉语、日语、英语、法语等,都可以用一个数字向量来表达其语义。以往,大家都只是猜测。谷歌翻译已经将这项技术商业化了,大家都认为是可行的。
第二件事是“可微”,那么什么是可微?比如一个词,腹泻和胃痛,字面上不一样,但谁都知道这两个是同义词。如果我们将其表示为相量,则从中减去 0.1。那是同义词吗?之前没有办法。用字母代替腹泻并再次减1是什么意思?本来就很无聊。所以之前的词汇是离散的,不可微的。现在我们已经找到了一个词向量。这个词向量是一个数字向量,可以微分。
第三件事是“可编辑”。如何一起编辑多个单词的词向量?就像拼接基因一样,我可以制作文章摘要、中心思想和关键词,所以词向量仍然是可编辑的。在此之前,大家一直觉得这是一个学术研究课题,能否实现还不确定。
但谷歌翻译上线后,业界基本没有异议,称这基本可行。也就是说,为什么说它取得了重大的学术突破,意义在于它证明了一种跨自然语言表达可区分和可编辑语言的新方法。
谷歌翻译不仅仅是一个翻译软件,它还是一种处理自然语言的新方法。
在医学领域,在构建大量病例时,除了传统的其他方法外,我们还可以使用sequence to sequence技术来构建病例。比如发生什么样的疾病,发生在什么地方,疾病会有很多属性,位置也会有很多属性,所以实际上词之间就有这种语义联系。
我们可以利用这项技术将自然语言写成句子,然后翻译成结构化的表格。谷歌翻译使用的序列到序列不限于翻译。它实际上是机器阅读的通用方法,所以它的意义是非常大的。
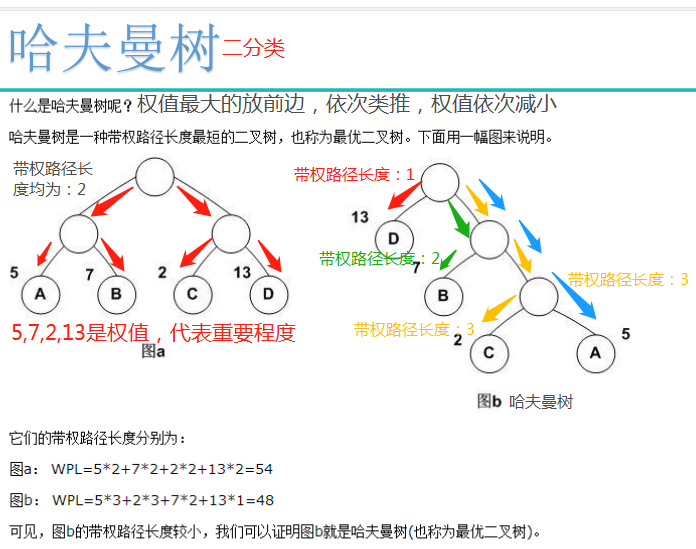
对于谷歌翻译的整个机制,谷歌仍然是一家有道德感的公司。他非常愿意将自己的一些内部细节写进论文并发表,这样每个人都可以一窥他是如何做到的。这篇论文非常有名。这篇论文的核心其实就是下面这张图。看懂了这张图,整篇论文就明白了。
这张图说明了什么?如果有汉译英的例子,“知识就是力量”,最终输出的是“知识就是力量”,输入的是中文,翻译成英文是它的主要目的。
它是如何做到的?其实有几个步骤:
其中使用的技术也称为“编码器”和“解码器”。另一种说法是“sequence to sequence”,一般来说,是谷歌翻译的核心技术。
这个地方有几样东西。刚才我们说为什么谷歌翻译的核心技术是划时代的?
之前说了三个关键词:一是“跨自然语言”,二是“可微分”,三是“可编辑”。上图中的例子是将中文变成数字语言,然后将数字语言翻译成英文。
大家可以想一想,能不能把中文翻译成数字语言,再从数字语言翻译成法语?当然这是可能的。同样,现代白话文可以先翻译成数字语言,再翻译成古汉语文言文。
给你一段现代汉语文本,翻译成数字语言,然后从数字语言中得到中心思想,或者说一段汉语,把它翻译成数字语言,然后把它从数字语言。这就是它的力量。
要解释这件事背后的原因,其实它有几个技术要素,包括如何生成词向量,词向量是什么,给你一个词或词“知识”,你把它翻译成数字向量,这称为词向量。生成这个词向量,这是第一件事。这里的核心问题是语言模型,用于生成词向量。这就是我们将在本文中讨论的内容。
在本系列讲座中,我们还将讨论其他主题。不仅是词向量,一个句子也有很多词向量。您必须对其进行编辑才能成为语义表示。什么是编辑器?LSTM 用于谷歌翻译。Facebook前段时间发了一篇论文,他用CNN来编辑。如何编辑语义,这是第二个话题。
第三个话题是注意力。解码时,您必须将其翻译成德语。哪个德语词汇是最合适的词汇?这里使用了一个注意力机制,顺序到序列还有另一个概念,即注意力聚焦。
关注后扩展是什么?目前的attention只是sequence to sequence的字面意思,没有先验知识。我们能否将知识图谱整合到注意力中,这意味着我们会有一些先验知识。这是第四个话题。如何利用符号知识图谱和联结仿生模型,让这两个完全独立的学派走到一起。
迄今为止,业界最好的是由CMU的Eric Xing教授制作的学生-教师模型。那天和君哥商量的时候,君哥说他有新方法。他说他在注意力上做了一个小把戏。听完后,我开始谈论它。我把那个东西叫做 Sun 的方法。这是一件了不起的事情,超级简单但超级有用。我这里就亲自讲,先讲师生模式,再讲孙老师的方法。
最后一个主题是评估函数。训练后还是不行或有缺陷怎么办?我们需要一个评估函数,你现在通常会用到它,但实际上有很多问题需要研究。讲完整个sequence到sequence的5大技术要素谷歌翻译出现恶毒攻击中国词汇,大家基本就明白了。
但为什么人们认为这听起来更难呢?主要的问题是,当我们谈论它的时候,我们总是把五个话题一下子混在一起,每个人自然有点困惑。怎么做?突破每一个。所以让我们制作一个系列。本文先讲第一个话题:“用语言模型生成词向量”。
使用语言模型生成词向量
词向量生成方法,业界最流行的方法是用语言模型(language model)来做,提这个方法提三个人,第一个是徐伟,他是1998年第一个提出语言的制作模型,然后给了图片中的第二个人一个巨大的启示。
第二人是 Yoshua Bengio,深度学习世界排名前三。他写的一篇论文非常有名,基本奠定了如何使用语言模型和词向量的整个方法论的基础。这篇论文发表后,跨时代发生了巨大的突破。
从工程的角度来说,现在基本怎么做词向量,大家觉得没有什么争议。最终,谷歌工程师 Tomas Mikolov 是屏蔽词向量的人。大家都知道这个词向量是他做的。

今天我们主要说说这个机制是怎么做的,以及业界对这个模式会有什么疑问。
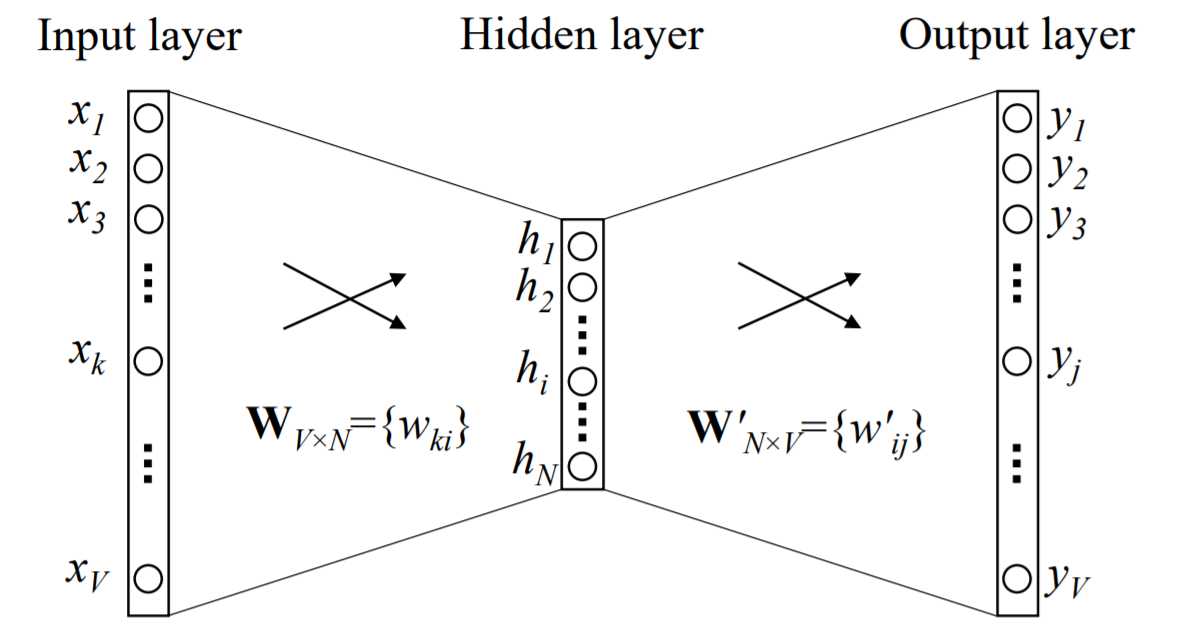
上图是 Bengio 的著名论文。每个人在学习的过程中都读过很多论文,印象深刻的论文并不多,但是这篇论文会给你留下非常深刻的印象。论文讲了一个非常强大的想法,整篇论文一口气读完,对我们来说没有任何障碍就完成了。这是非常愉快的。
如果你能看懂上图,这篇论文就基本看懂了。论文首先讨论的是语言模型。这种语言模型非常简单。就是给你一篇文章,文章由几个句子组成,每个句子由几个单词依次组成。
现在的问题是,我如何预测接下来应该出现哪个单词?它的概率是多少?这就是语言模型。
比如给你这句话,“人工智能医生帮助人类医生提高临床效率”。如果我先告诉你“人工智能”,你猜接下来会出现什么词?下一个可能有很多词,任何词都可能,可能是“医生”,可能是“帮助”等等。在这里,我先给你上一个字。我想猜猜“博士”以后出现的概率是多少?
这个语言模型怎么做?其实原因很简单。例如:我先将图片上的句子:“人工”、“智能”、“医生”、“帮助”……,分开后数词,每次出现“人工”时数,接下来是什么“聪明”有几个字?我们可以做统计。
所以后来提出了一种叫做N-gram的方法。例如,如果一个句子前面是“artificial”,后面是“intelligence”,那么“intelligence”出现的概率远大于“人工肥料”等其他带有“artificial”的词,那么我们认为“artificial Intelligence”可能是一个Phrases,这两个词经常放在一起,这种方法叫做N-gram。
它完全依赖于统计数据。它是否揭示了“人工”的语义和“智能”的语义,但它是一种语言模型。现在的问题是 Bengio 对语言模型做了两处改动。
根据上面的公式,第一行是最原始的语言模型。给定句子中间的前一句中的单词,现在我们要猜测该单词出现在下一个位置的概率。比如上一句“人工智能医生”,我现在想猜测“医生”后面出现“帮助”这个词的概率。这是它的原始语言模型。如果句子从第一个单词开始到您要预测的下一个位置,我将继续增长。
从第二行开始,做一点修改,每次给定一个定长窗口t,把前面的字倒过来。如果我将语言模型限制为固定长度的窗口,它会稍微降低准确性。这个给定长度的窗口 t 有一个学术名称,它是 N-gram,其中 N 等于我们中的 T。

这件事与本吉奥的工作无关。Bengio、许巍等人做了什么?
首先,从第三行开始,前面的单词不再是原来的Z符号,它先把它翻译成一个数字向量,我用g表示这是一个100维或200维或A 256-维或512维的数字向量从这边变换到这边,成为词向量。
第二件事是,您的条件概率使用什么函数来模拟?N-gram 中什么都没有,它是一个统计概率。从第四行开始,在 Bengio 的工作中,他使用了一个非常简单的神经网络来模拟条件概率。
所以他做了两件事。第一件事是将原始单词和符号从 N-gram 变成数字向量,第二件事是使用神经网络来模拟概率。
虽然这看起来很简单,但真的很神奇。看上图,人少。
第一,首先,我们需要训练这个神经网络来训练词向量的转换函数。这时候会需要很多参数,会用到很多训练语料。这些用于训练语言模型的训练语料从哪里来?很容易找到,任何文章都可以作为训练语料库,而且数量几乎是无限的。这是它的第一个优势。
那么问题来了,这种训练是无监督学习还是有监督学习?这种训练不需要打上无监督学习的标签,但是从它训练的输入输出来看,也是有监督的学习,所以边界非常宽。你可以说它是无人监督的,或者它有。监督。
监督学习是一种机器学习任务,它从标记的训练数据集中推断函数。
无监督学习是基于未知类别(未标记)的训练样本解决模式识别中的各种问题。
第二个优势,它是如何整体训练的?词到词向量的转换非常准确,前提是:
然后整个函数 g 将非常合适地组合在一起。但是一开始你不知道函数 g 是什么。假设函数g以一个随机词(值)开头,但是你应该知道它适合哪个词(值),并且两个词(值)中间会有一段距离。这时候,调整词向量的参数和神经网络的参数,不断调整,直到两者非常接近。这就是语言模型训练的全过程。
所以只要你知道这个神经网络是如何训练的,就没有那么复杂了。好在它的训练语料库几乎是无限的,只要你有足够的计算资源就可以放上去,所以模型非常简单。这就是 Bengio 谈到使用自然语言模型来训练词向量的方式。

这篇论文一出,立刻引起了冲动。比如,有人写过这样一篇文章,《自然语言(几乎)复兴》。重启炉子的想法,意味着之前的方法不好,需要重启。为什么不修复它,而是重新开始?因为方法变了。
为什么方法论发生了变化?回到开头一段,因为我发现了一种“跨越自然语言的超级语言”、一种“基因语言”、一种“数字语言”,而且它是不断可微分和可训练的。
他不仅说一个词可以算作它的词向量,而且一个句子中的每一个词都变成了一个词向量,整个句子就变成了一组词向量,也可以用于这组词向量。编辑,删掉了它的中心思想,删掉了它的语义和语法结构。
这意味着整个方法论都发生了变化,以至于有人会写一篇论文说我们必须重新开始。原来,这篇论文中预测的几件事情,几年后都变成了现实。最著名的证据是谷歌翻译。谷歌翻译基本上证明了这三件事在自然语言中是完全正确的,可区分的,可编辑的。
即便如此,也会有一些疑问,他们会是怎样的疑问?
是托马斯·米科洛夫。他的贡献主要是他把词向量的工程细节做得非常完美,但是他在论文中提出了一个证明,证明词向量确实包含语义。
这是他的著名论文,这篇论文中所有的词向量基本都是按照这个规则做的。这篇论文的结论有间接证据。它不能说词向量的前几个字节的语义是什么,但它会给你一些证据谷歌翻译出现恶毒攻击中国词汇,表明这些字节似乎确实包含一些语义。意思。
例如,给定两个词“Athens”和“Greece”,Athens是希腊的首都,对应“Oslo”和“Norway”,Oslo是挪威的首都,“Athens”有词向量,“Greece” "有一个词向量,"Oslo"也有一个词向量,"Norway"也有一个词向量。我减去了这两个词向量。大写词向量减去国家词向量。“Athens”的词向量减去“Greece”的词向量几乎等于“Oslo”的词向量减去“Norway”的词向量。词向量,这太神奇了。
Tomas Mikolov 说,通过这样一个简单的词向量减法实验,我从侧面反映了雅典的词向量和希腊的词向量确实暗示了首都和国家之间的某种关系。同样的减法思想也可以表达状态与状态资本的关系。
另外,兄妹的词向量相减等于孙子与孙女的相减。然后他说形容词和副词的关系也可以用词向量来表达。词向量不仅可以体现某种语义,还可以体现某种语法关系,堪称神仙之作。事情,但这只是一个间接的证据。
最后还有一个更有力的证据,就是前面提到的翻译。翻译的难度远比在这两个词之间建立某种语义关系要困难得多。汉译英准确不准确,大家一看便知。
如果现在大家都认为翻译准确,从中文到数字语言,听起来有点靠谱。但翻译仍然是旁证,但比前一个字减法的旁证更有力、更确凿的证据。
| 广告位 |




